
Overview: This material should avoid being a repeat of the summary since that is above. We develop algorithms for detection, recognition and object/agent/event categorization for multi-agent tasks in complex, uncertain and dynamic environments of unknown complexity. Our algorithms can exploit multiple sensors mounted on various platforms with mobility and/or control, to infer a representation of the environment suitable for agents to interact with it and within it.
Examples of applications of our methods include:
- Heterogeneous UxV team performing public security missions, e.g. in airports and train stations
- Multi-camera system used to learn pedestrian motion patterns at busy intersections
- Team of agents surveying adversarial activity in unknown environments
|
Distributed multi-agent system architecture: Description of this figure. I really tried to find a nice markdown way of doing this. Images are sizeable (see below), but putting text underneath looks gross and tables seem even worse. There is probably a cleaner way to do this via css. It is also possible that there is some image resource method in Hugo, but if so, I haven't figured it out. BUT It still looks better than what is below. Besides, videos have to be included this way as well, so might as well use it. |
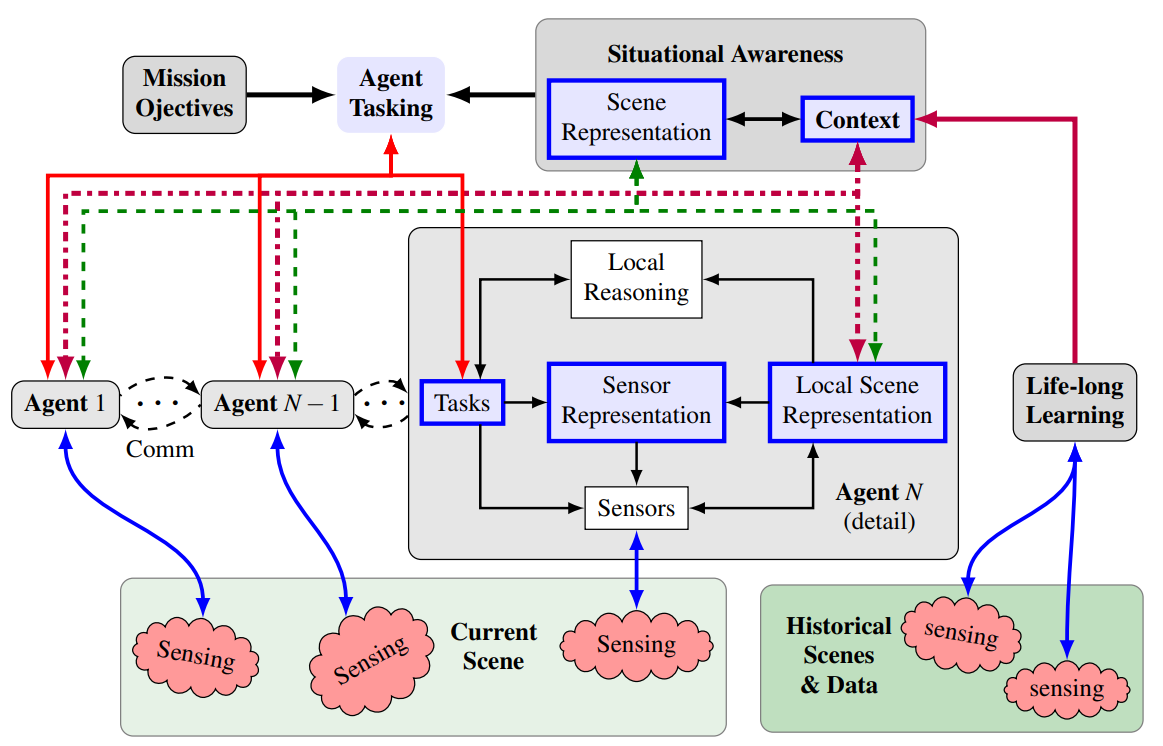
Our research designs a number of key elements for a proposed distributed multiagent architecture in Fig. 1. The key part is that the Situational awareness is comprised of a scene representation (encodes physical and semantic attributes of a scene, parameter uncertainty, and enables efficient reasoning over scene properties) and context (encodes prior knowledge of a given scene obtained via a Life-long learning process that summarizes historical data). Agents utilize a local mission-specific scene representation combined with a sensor representation that distinguishes task-relevant sensor parameters from nuisances. Additionally, agents have a means of both updating a global scene representation as well as sharing knowledge. The overall mission and uncertainty reduction in the situational awareness is accomplished via agent tasking and by utilizing contextual information obtained via the long time-scale learning process. Planning is distributed – agent tasking allocates tasks to agents according to global information needs while individual agents reason and operate autonomously, cooperatively when necessary, to perform their assigned tasks.
Scene representation:
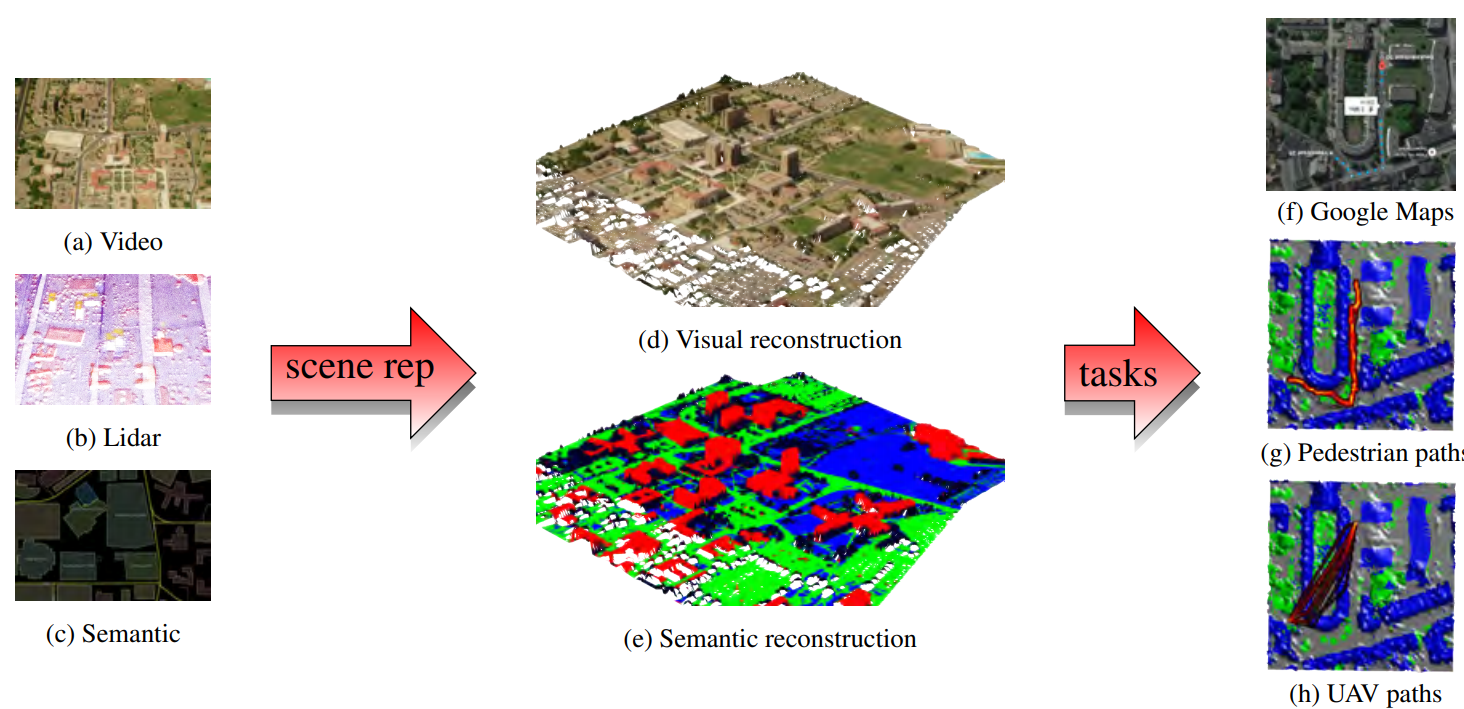 Figure 2. Joint geometric, appearance and semantic representation of a scene.
Figure 2. Joint geometric, appearance and semantic representation of a scene.
We developed a probabilistic generative models for integrating multi-modal sensor data and semantic information within a consistent Bayesian nonparametric statistical framework. Fig. 2 integrates Lidar, aerial imagery, and geo-tagged semantic observations to construct a joint geometric, appearance and semantically categorized representation of a scene. The approach extends previously proposed methods by imposing a joint BNP prior over geometry, appearance, and semantic labels leading to more accurate reconstructions and the ability to infer missing contextual labels via joint sensor and semantic information. Mission planning (for example path planning) considers scene attributes, including their inherent uncertainty, as well as the capabilities of the agent (e.g. UAV versus ground based). Uncertainty in the mission success explicitly drives the need for additional information gathering and/or contextual information.
Distributed learning:
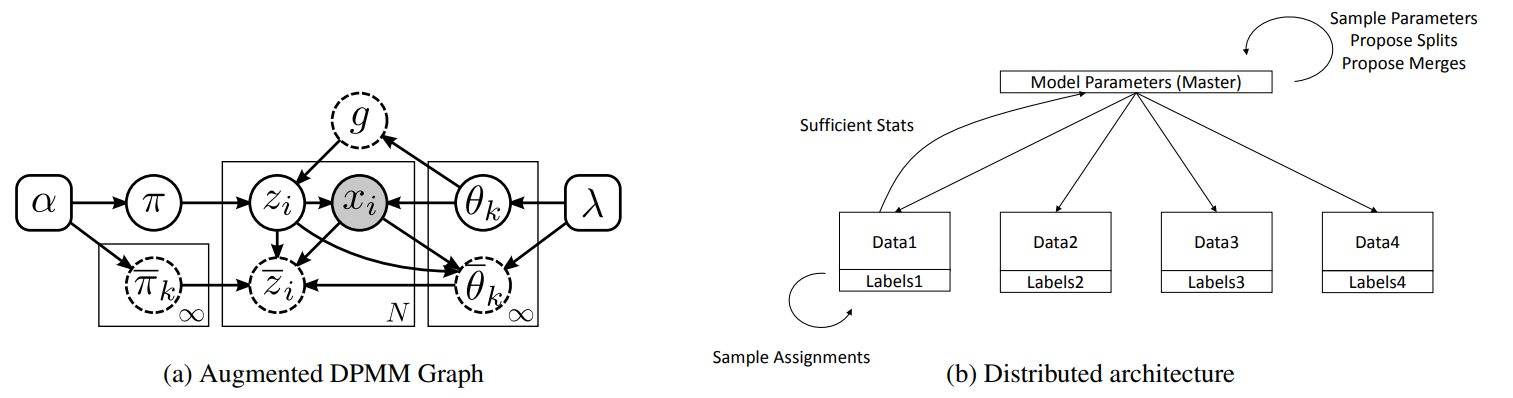 Figure 3. Graphical model and architecture for distributed learning of DPMMs.
Figure 3. Graphical model and architecture for distributed learning of DPMMs.
We developed a class of efficient parallelizable Markov chain Monte Carlo (MCMC) methods for inference in mixture and hierarchical mixture models. Fig. 3a depicts the associated augmented graphical model for the Dirichlet process (DP) case, a similar graph extension exists for Hierarchical Dirichlet process (HDPs). While the primary motivation for developing the inference procedure was to enable exact inference using DP and HDP models over large data sets, the approach is general and applicable to general finite and hierarchical models. Importantly, the formulation guarantees detailed balance and as such preserves desirable theoretical guarantees for Bayesian inference, i.e. convergence to the model distribution. Implicitly, the approach was formulated using a shared memory assumption where all processors have full access to all data, limiting its utility in the distributed settings we envision for the proposed research project. Recently, however, we have extended this method to the distributed data setting allowing data to be partitioned across processing units (e.g., multiple agents). This eliminates the shared memory assumption, but induces additional communication and coordination. The architecture is shown in Fig. 3b where autonomous processing units coordinate inference via shared sufficient statistics to a central coordinating agent. Importantly, all of the theoretical guarantees of the original formulation are preserved.
Project Title: Context and Task-aware Active Perception for Multiagent Systems
Acknowledgement: This research was partially supported by ONR (Award No. N00014-17-1-2072)